import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
# SKlearn (denk om "pip install scikit-learn" en NIET "sklearn"):
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report
# load the data
url = 'titanic-train.csv'
df = pd.read_csv(url)
#df.columns = ['PassengerId','Survived','Pclass','Name','Sex','Age','SibSp','Parch','Ticket','Fare','Cabin','Embarked']
# inspect the data
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
df.describe()
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 446.000000 | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| std | 257.353842 | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 223.500000 | 0.000000 | 2.000000 | 20.125000 | 0.000000 | 0.000000 | 7.910400 |
| 50% | 446.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.500000 | 1.000000 | 3.000000 | 38.000000 | 1.000000 | 0.000000 | 31.000000 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
df.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
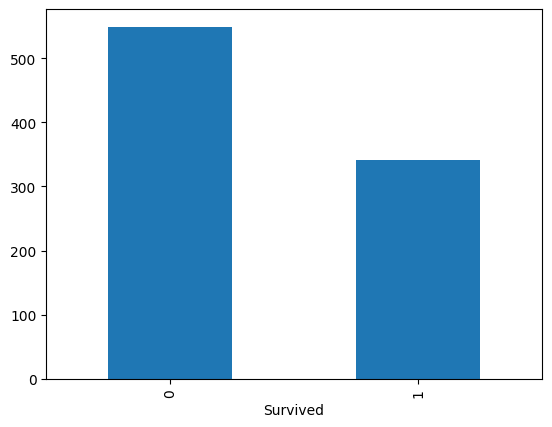
# Check de class variabele, de variabele die we willen voorspellen a.d.h.v. de features
df['Survived'].value_counts().plot(kind='bar')
<Axes: xlabel='Survived'>
## Check missing values
# We kunnen makkelijk checken op missing values met de isnull methode van pandas
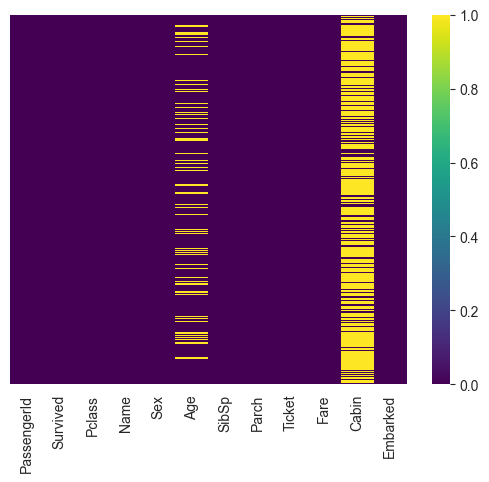
df.isnull().sum()
# de set bevat missing values op Age en Cabin (en Embarked)
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
# Kan ook grafisch
sns.set_style("whitegrid")
sns.heatmap(df.isnull(), yticklabels=False, cmap="viridis")
<Axes: >
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
# plot the data
df.Age.hist(bins=20, label='leeftijd')
plt.legend()
<matplotlib.legend.Legend at 0x1d938c62db0>

# data is wijd verspreid, dus hoe data missing values in te vullen?
# Is er een relatie met klasse?
sns.boxplot(x='Pclass', y='Age', data=df, palette='hls', hue='Pclass', legend=False)
<Axes: xlabel='Pclass', ylabel='Age'>
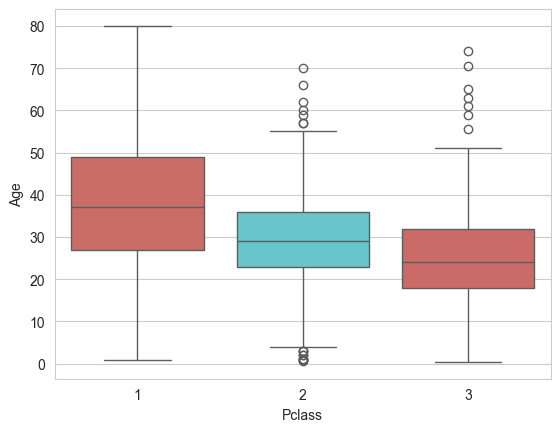
Grof gezegd kunnen we zeggen dat hoe jonger een passagier is, hoe groter de kans is dat hij in de 3e klas zit. Hoe ouder een passagier is, hoe groter de kans dat hij in de 1e klas zit. Er is dus een losse relatie tussen deze variabelen. Laten we dus een functie schrijven die de leeftijd van de passagier benadert, op basis van hun klasse. Uit de boxplot blijkt dat de gemiddelde leeftijd van de 1e klas passagiers ongeveer 37 is, de 2e klas passagiers 29 is en de 3e klas passagiers 24 is.
Laten we dus een functie schrijven die elke nulwaarde in de variabele Age vindt en voor elke nul de waarde van de Pclass controleert en een leeftijdwaarde toekent op basis van de gemiddelde leeftijd van passagiers in die klasse.
def age_approx(cols):
Age = cols.iloc[0]
Pclass = cols.iloc[1]
if pd.isnull(Age):
if Pclass == 1:
return 37
elif Pclass == 2:
return 29
else:
return 24
else:
return Age
df['Age'] = df[['Age', 'Pclass']].apply(age_approx, axis=1)
df.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
df.head(10)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| 5 | 6 | 0 | 3 | Moran, Mr. James | male | 24.0 | 0 | 0 | 330877 | 8.4583 | NaN | Q |
| 6 | 7 | 0 | 1 | McCarthy, Mr. Timothy J | male | 54.0 | 0 | 0 | 17463 | 51.8625 | E46 | S |
| 7 | 8 | 0 | 3 | Palsson, Master. Gosta Leonard | male | 2.0 | 3 | 1 | 349909 | 21.0750 | NaN | S |
| 8 | 9 | 1 | 3 | Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) | female | 27.0 | 0 | 2 | 347742 | 11.1333 | NaN | S |
| 9 | 10 | 1 | 2 | Nasser, Mrs. Nicholas (Adele Achem) | female | 14.0 | 1 | 0 | 237736 | 30.0708 | NaN | C |
# waarschijnlijk doen naam, ticket en cabin er niet toe, deze kunnen we verwijderen
df = df.drop(['Name','Ticket','Cabin'], axis=1)
df.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Sex 0
Age 0
SibSp 0
Parch 0
Fare 0
Embarked 2
dtype: int64
# verwijderen van de rijen met de twee waardes nul in de Embarked zal niet veel uitmaken
df.dropna(inplace=True)
df.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Sex 0
Age 0
SibSp 0
Parch 0
Fare 0
Embarked 0
dtype: int64
df.info()
<class 'pandas.core.frame.DataFrame'>
Index: 889 entries, 0 to 890
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 889 non-null int64
1 Survived 889 non-null int64
2 Pclass 889 non-null int64
3 Sex 889 non-null object
4 Age 889 non-null float64
5 SibSp 889 non-null int64
6 Parch 889 non-null int64
7 Fare 889 non-null float64
8 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(2)
memory usage: 69.5+ KB
df.head(3)
| PassengerId | Survived | Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S |
| 1 | 2 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C |
| 2 | 3 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S |
#Sex en Embarked moeten numeriek gemaakt worden
df['Sex'] = df['Sex'].map({'female': '1', 'male': '0'})
df.head()
| PassengerId | Survived | Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | 0 | 22.0 | 1 | 0 | 7.2500 | S |
| 1 | 2 | 1 | 1 | 1 | 38.0 | 1 | 0 | 71.2833 | C |
| 2 | 3 | 1 | 3 | 1 | 26.0 | 0 | 0 | 7.9250 | S |
| 3 | 4 | 1 | 1 | 1 | 35.0 | 1 | 0 | 53.1000 | S |
| 4 | 5 | 0 | 3 | 0 | 35.0 | 0 | 0 | 8.0500 | S |
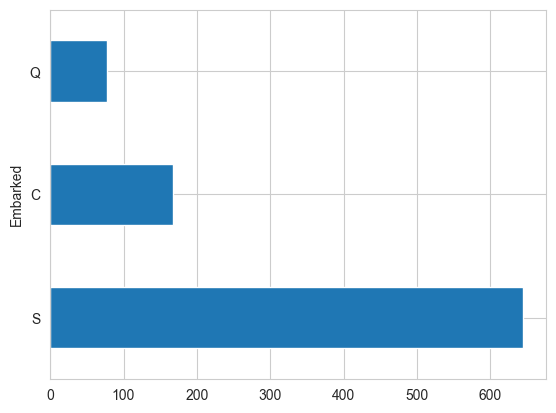
df.Embarked.value_counts().plot(kind='barh')
<Axes: ylabel='Embarked'>
df['Embarked'] = df['Embarked'].map({'C': '1', 'S': '2', 'Q': '3'})
df.head()
| PassengerId | Survived | Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | 0 | 22.0 | 1 | 0 | 7.2500 | 2 |
| 1 | 2 | 1 | 1 | 1 | 38.0 | 1 | 0 | 71.2833 | 1 |
| 2 | 3 | 1 | 3 | 1 | 26.0 | 0 | 0 | 7.9250 | 2 |
| 3 | 4 | 1 | 1 | 1 | 35.0 | 1 | 0 | 53.1000 | 2 |
| 4 | 5 | 0 | 3 | 0 | 35.0 | 0 | 0 | 8.0500 | 2 |
df.info()
<class 'pandas.core.frame.DataFrame'>
Index: 889 entries, 0 to 890
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 889 non-null int64
1 Survived 889 non-null int64
2 Pclass 889 non-null int64
3 Sex 889 non-null object
4 Age 889 non-null float64
5 SibSp 889 non-null int64
6 Parch 889 non-null int64
7 Fare 889 non-null float64
8 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(2)
memory usage: 69.5+ KB
df['Sex'] = pd.to_numeric(df['Sex']) # alt.: df['Sex'] = df['Sex'].astype('int')
df['Embarked'] = pd.to_numeric(df['Embarked'])
df.info()
<class 'pandas.core.frame.DataFrame'>
Index: 889 entries, 0 to 890
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 889 non-null int64
1 Survived 889 non-null int64
2 Pclass 889 non-null int64
3 Sex 889 non-null int64
4 Age 889 non-null float64
5 SibSp 889 non-null int64
6 Parch 889 non-null int64
7 Fare 889 non-null float64
8 Embarked 889 non-null int64
dtypes: float64(2), int64(7)
memory usage: 69.5 KB
df.head()
| PassengerId | Survived | Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | 0 | 22.0 | 1 | 0 | 7.2500 | 2 |
| 1 | 2 | 1 | 1 | 1 | 38.0 | 1 | 0 | 71.2833 | 1 |
| 2 | 3 | 1 | 3 | 1 | 26.0 | 0 | 0 | 7.9250 | 2 |
| 3 | 4 | 1 | 1 | 1 | 35.0 | 1 | 0 | 53.1000 | 2 |
| 4 | 5 | 0 | 3 | 0 | 35.0 | 0 | 0 | 8.0500 | 2 |
# get X (features) en y (class/category)
y = np.array(df['Survived'])
X = np.array(df.iloc[:,2:9]) # slice is 'up to but not including'
X.shape
(889, 7)
# normaliseer (gemiddelde eraf en delen door de standaarddeviatie, zodat het op een normaalverdeling gaat lijken)
def normalize(X):
scaler = StandardScaler()
scaler = scaler.fit(X)
X = scaler.transform(X)
return X
X = normalize(X)
X
array([[ 0.82520863, -0.73534203, -0.53167023, ..., -0.47432585,
-0.50023975, 0.19880372],
[-1.57221121, 1.35991138, 0.68023223, ..., -0.47432585,
0.78894661, -1.74335569],
[ 0.82520863, 1.35991138, -0.22869462, ..., -0.47432585,
-0.48664993, 0.19880372],
...,
[ 0.82520863, 1.35991138, -0.38018243, ..., 2.00611934,
-0.17408416, 0.19880372],
[-1.57221121, -0.73534203, -0.22869462, ..., -0.47432585,
-0.0422126 , -1.74335569],
[ 0.82520863, -0.73534203, 0.22576881, ..., -0.47432585,
-0.49017322, 2.14096313]])
Na al deze verkennings- en preparatiestappen gaan we eindelijk het model maken, trainen en evalueren!#
# split: 70% trainingsdata en 30% testdata
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = .3, random_state=42)
# train model
logReg = LogisticRegression()
logReg.fit(X_train, y_train)
y_pred = logReg.predict(X_test)
# evalueer
from sklearn.metrics import confusion_matrix
confusion_matrix = confusion_matrix(y_test, y_pred)
print(confusion_matrix)
[[138 29]
[ 26 74]]
print(classification_report(y_test, y_pred))
precision recall f1-score support
0 0.84 0.83 0.83 167
1 0.72 0.74 0.73 100
accuracy 0.79 267
macro avg 0.78 0.78 0.78 267
weighted avg 0.80 0.79 0.79 267
Extra#
Correlaties zijn een goede manier om te kijken welke features relevant zijn voor Survived en welke niet.
corr_matrix = df.corr()
corr_matrix
| PassengerId | Survived | Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | |
|---|---|---|---|---|---|---|---|---|---|
| PassengerId | 1.000000 | -0.005028 | -0.035330 | -0.043136 | 0.033008 | -0.057686 | -0.001657 | 0.012703 | -0.017487 |
| Survived | -0.005028 | 1.000000 | -0.335549 | 0.541585 | -0.052051 | -0.034040 | 0.083151 | 0.255290 | -0.126753 |
| Pclass | -0.035330 | -0.335549 | 1.000000 | -0.127741 | -0.405549 | 0.081656 | 0.016824 | -0.548193 | 0.307324 |
| Sex | -0.043136 | 0.541585 | -0.127741 | 1.000000 | -0.083730 | 0.116348 | 0.247508 | 0.179958 | -0.023175 |
| Age | 0.033008 | -0.052051 | -0.405549 | -0.083730 | 1.000000 | -0.242807 | -0.170089 | 0.120938 | -0.076559 |
| SibSp | -0.057686 | -0.034040 | 0.081656 | 0.116348 | -0.242807 | 1.000000 | 0.414542 | 0.160887 | 0.031095 |
| Parch | -0.001657 | 0.083151 | 0.016824 | 0.247508 | -0.170089 | 0.414542 | 1.000000 | 0.217532 | -0.035756 |
| Fare | 0.012703 | 0.255290 | -0.548193 | 0.179958 | 0.120938 | 0.160887 | 0.217532 | 1.000000 | -0.269588 |
| Embarked | -0.017487 | -0.126753 | 0.307324 | -0.023175 | -0.076559 | 0.031095 | -0.035756 | -0.269588 | 1.000000 |
corr_matrix['Survived']
PassengerId -0.005028
Survived 1.000000
Pclass -0.335549
Sex 0.541585
Age -0.052051
SibSp -0.034040
Parch 0.083151
Fare 0.255290
Embarked -0.126753
Name: Survived, dtype: float64
Grafisch#
sns.heatmap(corr_matrix, annot=True, vmax=1, vmin=-1, center=0, cmap='vlag')
<Axes: >
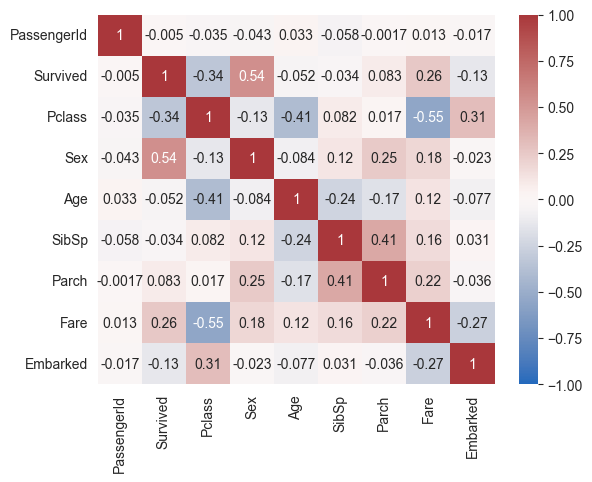
Klopt dit met de gewichten die het LogReg-model gevonden heeft?#
weights = logReg.coef_
weights
array([[-0.92207254, 1.31801161, -0.65228026, -0.48223878, -0.05739479,
0.12816244, -0.16910035]])
weights = weights[0].tolist()
weights
[-0.922072543559232,
1.318011610293939,
-0.6522802624930832,
-0.482238782010131,
-0.057394788324977346,
0.1281624355258713,
-0.16910034556667025]
features = ['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked']
fw = zip(weights, features)
tuple(fw)
((-0.922072543559232, 'Pclass'),
(1.318011610293939, 'Sex'),
(-0.6522802624930832, 'Age'),
(-0.482238782010131, 'SibSp'),
(-0.057394788324977346, 'Parch'),
(0.1281624355258713, 'Fare'),
(-0.16910034556667025, 'Embarked'))
Class en Sex zijn naar verwachting hoog. Age is hoger dan verwacht, Fare lager.